



本文由麻省理工学院的Max W. Shen、哈佛大学的Alvin Hsu和哈佛大学布罗德研究所的David R. Liu共同撰稿。
在过去六个月中,COVID-19对我们的世界产生了巨大影响——截至2020年6月4日,COVID-19在全球造成了约38万人死亡(谷歌在6月4日提供的统计数据)。许多国家进入封锁状态长达数周至数月,暂停或终止了相当一部分劳动力的就业。
湿实验室的科学家也不例外——由于COVID-19,世界各地实验室中精心设计的实验被无限期搁置。在我们的实验室,我们有兴趣研究COVID-19对全球科学活动的影响。然而,如果没有广泛、公正的数据,这类开放式问题很难定量地回答。因此,我们选择检查的数据集刘实验室质粒来自Addgene的请求,作为我们特定科学子领域的全球活动的代理。
质粒请求与论文发表相关
数据集包含6年来35篇论文的11426个质粒请求(数据由Addgene在5/26/20提供,包含从5/22/14到5/19/20的请求)。每篇论文有1-32个质粒,总共有2 - 2590个请求。我们收到了来自56个国家的质粒请求,但数据主要是美国(42%)、欧洲(23%)和中国(14%)。质粒请求的激增与流行论文的发表相对应。
 |
| 图1:按日期划分的质粒请求。括号中表示每篇论文所订购的质粒总数。 |
粗略估计COVID-19对质粒请求的影响
在我们开始任何复杂的分析之前,我们首先以各种方式可视化我们的数据。用7天滚动平均值平滑我们的质粒顺序数据,让我们粗略地了解了COVID-19对我们的数据的影响程度。由于我们的大多数质粒订单来自美国和欧洲,我们看到相应的质粒需求活动在3月份左右下降。粗略估计,3月份的活动量约为2020年1月1日至3月1日期间的33%。
 |
图2:COVID-19对7天滚动均值平滑数据影响的简单近似 |
虽然这一全球近似值已经向我们展示了订单数据的粗略“COVID-19效应”,但它没有捕捉到世界不同地区在不同时间遭遇COVID-19的事实。最值得注意的是,1月中旬至3月中旬,中国比世界其他国家更早受到新冠肺炎疫情的影响。
为了更好地了解质粒顺序如何受到COVID-19大流行的影响,我们比较了每个地点每周质粒顺序的数量和新冠肺炎病例。我们观察到,如预期的那样,质粒顺序(左,蓝色)在新冠肺炎病例报告(右,红色)时急剧下降,可能是由于隔离
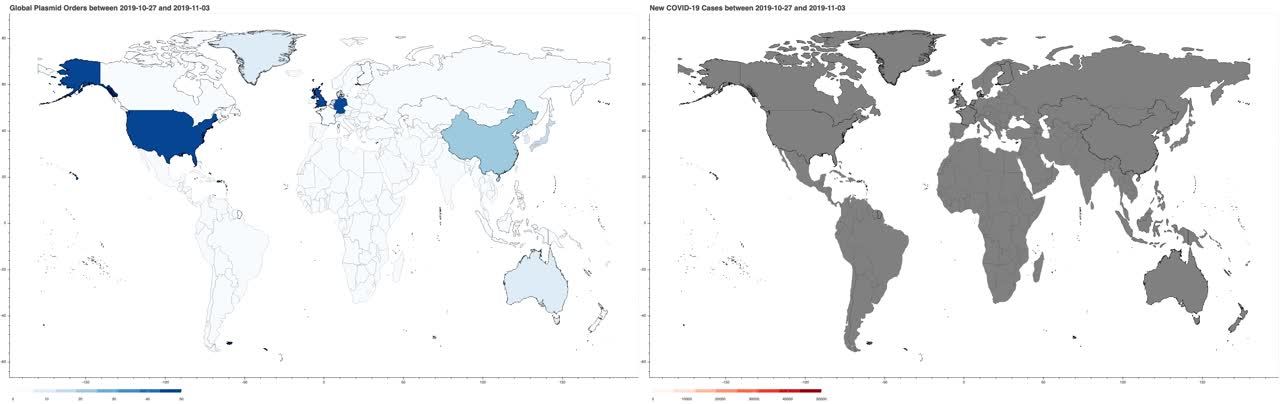
|
| 图3。展示质粒顺序和每周新冠肺炎病例的动画地图。 |
统计建模
注:如果统计建模不是你的拿手之处,请随意直接跳到结果.
为了开始对数据建模,我们首先选择以更细的时间粒度重新检查全局数据。对于每一篇论文,我们观察到对相应质粒的需求倾向于遵循指数衰减模型,在周末和重要节假日期间下降。
 |
| 图4:质粒请求轨迹显示了一个具有周末和假期效应的指数衰减需求模型。 |
基于这些观察,我们考虑了以下(无噪声)模型的数据:
 我们选择让yx(t)表示订购纸张的唯一pi或实验室的数量x在日期t.我们不能使用单个的质粒顺序,因为当PI或实验室下订单时,他们可能会同时订购多个质粒,这打破了泊松过程的统计独立性假设。这种修改也简化了对我们推断的参数的解释,因为科学生产力更好地解释为科学家或实验室下订单的速度。
我们选择让yx(t)表示订购纸张的唯一pi或实验室的数量x在日期t.我们不能使用单个的质粒顺序,因为当PI或实验室下订单时,他们可能会同时订购多个质粒,这打破了泊松过程的统计独立性假设。这种修改也简化了对我们推断的参数的解释,因为科学生产力更好地解释为科学家或实验室下订单的速度。
我们的模型将泊松过程中的可能性考虑为两个分量:x(t),z(t).x (t)描述了我们观察到的指数衰减过程,而z(t)将可能性乘以相应的因子z ift是在事件z.我们为模型考虑的“事件”是周末、圣诞节/新年和COVID-19封锁。为了让我们的模型对每个参数给出不确定性估计,我们向构成我们分布的每个项添加了对数正态噪声,结果是以下层次模型:

由于美国、欧洲和中国占据了我们所有质粒订单的75%以上,所以我们接下来的讨论将集中在这三个地区。这些地区都在不同的时间受到COVID-19的影响,因此我们将中国的COVID-19事件窗口定义为01/15/20 - 03/15/20,美国和欧洲的COVID-19事件窗口定义为03/11/20 - 05/19/20(数据集的最后日期)。为了提高模型的稳定性,我们只考虑了2020年10个以上唯一订单日期的10篇论文。
我们使用Pytorch中的随机梯度下降对每个区域拟合我们的模型,这给了我们每个参数的最大似然估计。由于数据似然的解析表达式包含泊松与多元对数正态似然乘积的棘手积分,因此我们用多元高斯-厄密求积逼近数据似然。
周末、寒假、新冠疫情对质粒请求的影响
 |
| 图5:推断的效果。值是推断的正常活动的百分比(唯一pi /实验室每天下订单的平均比率)的日期受到每个影响。 |
推断的参数表明,COVID-19导致各地区的科学家每天下订单的速度减少了2 - 5倍,欧洲受影响最大,中国受影响最小。回想起来,推断出来的周末效应通常比COVID-19效应更引人注目,尽管我们提醒读者,这不是一种因果解释——如果科学家以某种方式受到周末的影响,这种效应通常不会是相同的。

|
| 图6:模型适配。橙色线表示观测数据。蓝线是每篇论文的平均费率之和。绿线和红线分别表示每篇论文的均值+1和-1 std的和。 |

该模型捕捉到了周末、圣诞节、新年等,对新冠肺炎的影响非常好。然而,我们在中国的数据中观察到一个并发症——在1个月的时间里,从1/22/20-2/23/20,没有质粒请求。之后,从2/24/20-3/15/20(封锁结束)开始,请求活动似乎恢复正常。该模型拟合这两个离散阶段,对中国COVID-19影响的估计为62.3%。然而,很明显,如果我们认为1/22/20-2/23/20是中国封锁的更准确日期,那么观察到的数据与因COVID-19而将活动减少到零的无限倍是一致的。因此,根据我们认为中国COVID-19的日期范围,他们可能是受影响最大或最小的。这些结果突出了从中国相对稀疏的数据中估计参数的不稳定性和不确定性。
另外一个重要的警告是,我们的数据集只包含来自一个实验室的质粒序列,这限制了我们对COVID-19对科学活动影响的分析的解释范围。COVID-19对其他许多科学领域的影响可能会有所不同。
结论
 |
| 图7:按区域推断的平均效应。 |
总之,我们的模型推断,COVID-19导致各地区的科学家每天下订单的速度减少了2 - 5倍。我们对模型拟合的研究揭示了中国数据中存在的一些潜在不稳定性,因此我们建议对具有更多不确定性的中国数据解释模型结果。
非常感谢我们的客座博主,麻省理工学院的Max W. Shen,哈佛大学的Alvin Hsu和哈佛大学布罗德研究所的David R. Liu。
 Max Shen是麻省理工学院的博士生。他的研究将应用机器学习和统计方法用于基础科学发现和高影响应用。
Max Shen是麻省理工学院的博士生。他的研究将应用机器学习和统计方法用于基础科学发现和高影响应用。
 Alvin Hsu是哈佛大学的一名研究生。他对使用选择、进化和机器学习来解决化学和化学生物学中的难题感兴趣。
Alvin Hsu是哈佛大学的一名研究生。他对使用选择、进化和机器学习来解决化学和化学生物学中的难题感兴趣。
 David R. Liu, Merkin Institute主任,Broad Institute副院长;哈佛大学化学和化学生物学教授;霍华德·休斯医学研究所研究员刘的研究结合了化学和进化来阐明生物学,并使下一代疗法成为可能。启动编辑、碱基编辑、PACE和dna模板合成是他实验室首创的技术的四个例子。学习更多在这里.
David R. Liu, Merkin Institute主任,Broad Institute副院长;哈佛大学化学和化学生物学教授;霍华德·休斯医学研究所研究员刘的研究结合了化学和进化来阐明生物学,并使下一代疗法成为可能。启动编辑、碱基编辑、PACE和dna模板合成是他实验室首创的技术的四个例子。学习更多在这里.
Addgene博客上的其他资源188博金宝官网
- 了解更多关于COVID-19期间共享质粒
在Addgene.org上的资源
- 找到来自David Liu实验室的质粒
- 访问我们的COVID-19质粒和资源



留下你的评论